4k stars! A containerized vector retrieval RAG system that supports multi-modal input, hybrid search and knowledge graph construction.
By combining the advantages of information retrieval and natural language generation, RAG can not only accurately extract information from large-scale data, but also generate contextually relevant content based on this information, thus greatly improving the effectiveness of intelligent search and question and answer systems.
Many people think that if RAG processes a large number of documents, it may consume too many resources.
This statement makes sense, but it is not entirely accurate.
Working with very large file sets can indeed consume a lot of resources without good optimization, especially in the absence of efficient indexing or caching mechanisms.
However, the advantage of RAG technology lies in its ability to efficiently extract key information from large amounts of data and generate relevant content, so it is not particularly suitable for scenarios where only a small number of files are processed.
In actual use, RAG system design usually considers how to balance retrieval efficiency and generation quality under large-scale documents and data sets.
The open source RAG project I will introduce to you today is R2R, and a lot of optimization strategies have been made in this regard.
Of course, the biggest feature summarized by the author for this project is containerization, providing services through RESTful API, making it easier for developers to integrate and use.
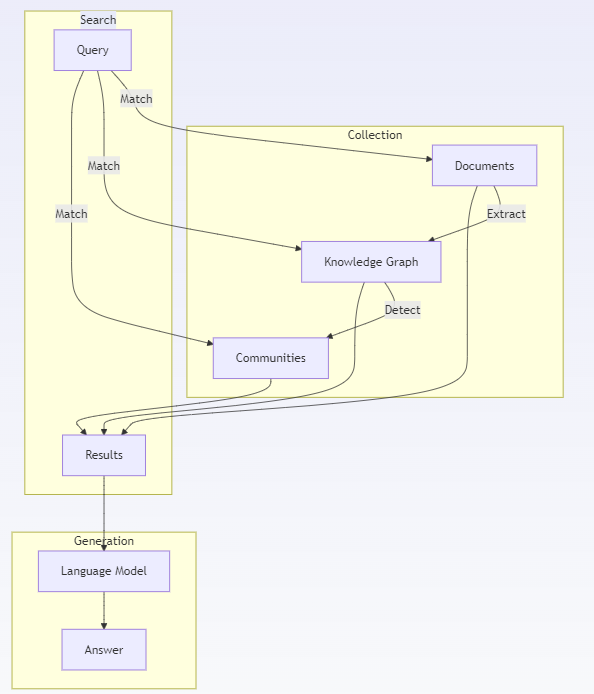
Project introduction
R2R (RAG to Riches) is an open source RAG system that improves the efficiency of information search and processing by combining retrieval and generation technologies. It supports content input in multiple formats (such as text, PDF, images, audio, etc.), can automatically extract and build knowledge graphs, and provides hybrid search functions to help users quickly find relevant information. Through its RESTful API, R2R provides developers with a flexible tool for building smarter search and content generation applications.
Features
📁Multi -modal ingestion:
Parse files in .txt, .pdf, .json, .png, .mp3 and other formats. and convert them into searchable, analyzable content. The ingestion process includes parsing, chunking, embedding, and optionally extracting entities and relationships to build a knowledge graph.

🔍Mixed search:
Combine semantic search and keyword search to improve the relevance of search results through reciprocal ranking integration.

🔗Knowledge graph:
Automatically extract entities and relationships and build a knowledge graph.
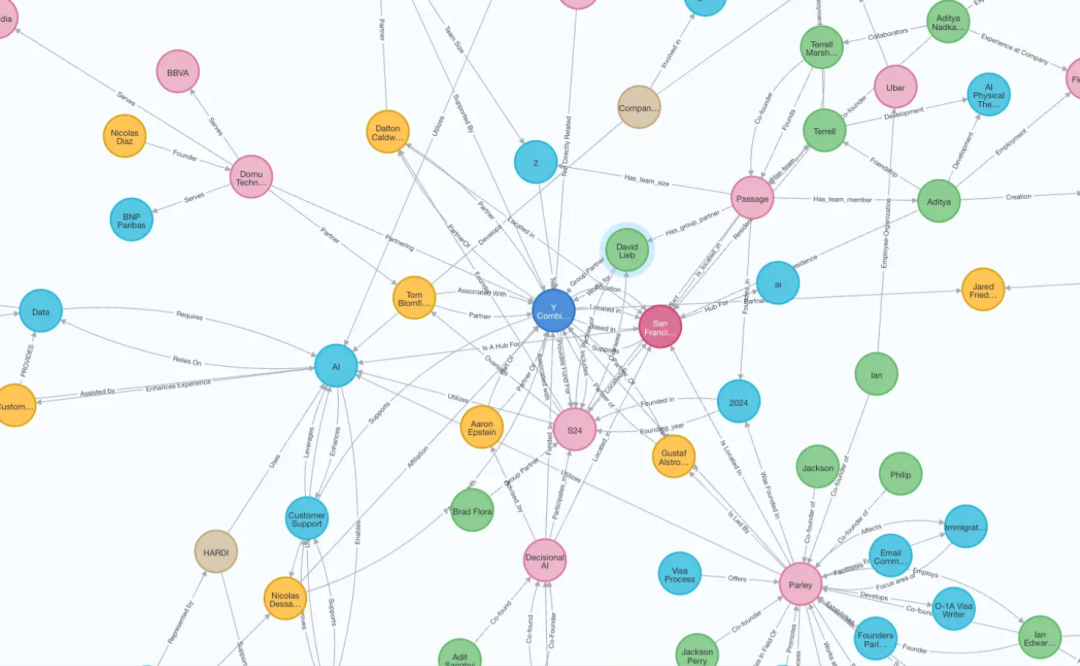
Adopt a two-level architecture:
Document level: Entities and relationships are first extracted and stored with the source document
Collection level: Collections act as soft containers that can contain documents and maintain corresponding diagrams
📊 GraphRAG:
GraphRAG extends traditional RAG with community detection and summarization capabilities in knowledge graphs. By understanding how information is clustered and connected in a document, this approach can provide richer context and more comprehensive answers.
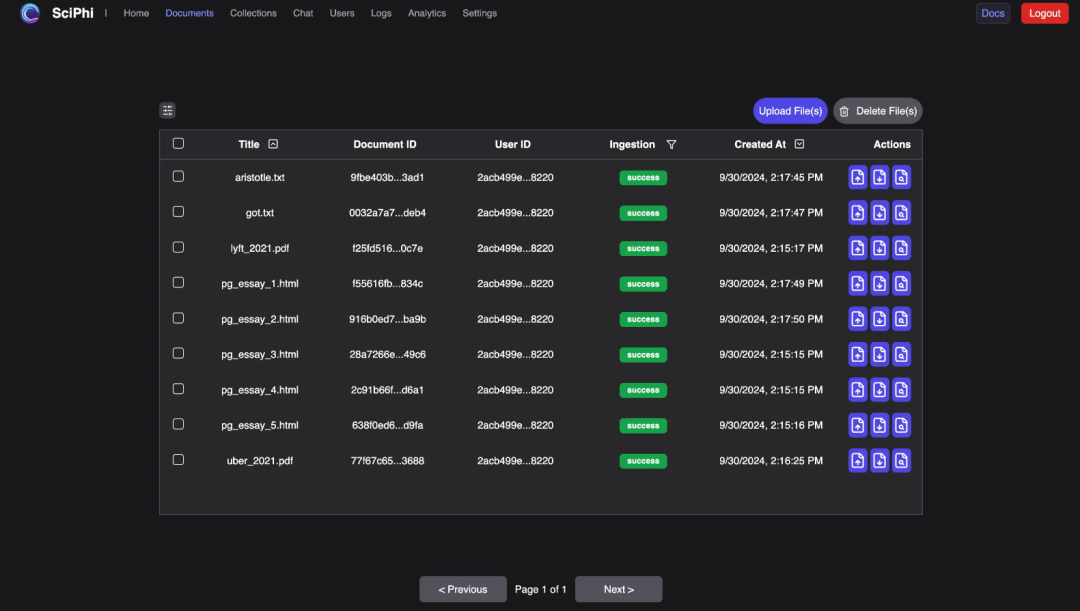
🗂️User management: Efficiently manage documents and user roles.
🖥️Dashboard:
An open source React+Next.js management dashboard that interacts with R2R through a GUI.
https://github.com/SciPhi-AI/R2R