GPT-4o is an open source implementation of voice interaction, an end-to-end multi-modal large model that can directly understand audio.
I don’t know if you have noticed a problem. Any scenario where large models are called through voice now will have delays and lead to poor user experience , such as AI companion hardware dolls, AI phone customer service, and AI girlfriends with real-time conversations.
Essentially, when talking to a big model through voice, you have to convert the speech into text and send it to the big model, and then convert the big model's answer into speech so that we can hear it.
This time-consuming back and forth resulted in less than perfect fluency and naturalness in our conversations with the large model.
Ultravox is an end-to-end multi-modal large model that can directly understand audio without the need to convert audio and text to each other.
Now that the version has been trained on Llama 3, Mistral and Gemma, the usability is very high.
Ultravox's speech understanding capabilities are close to those of GPT-4o's proprietary solutions.
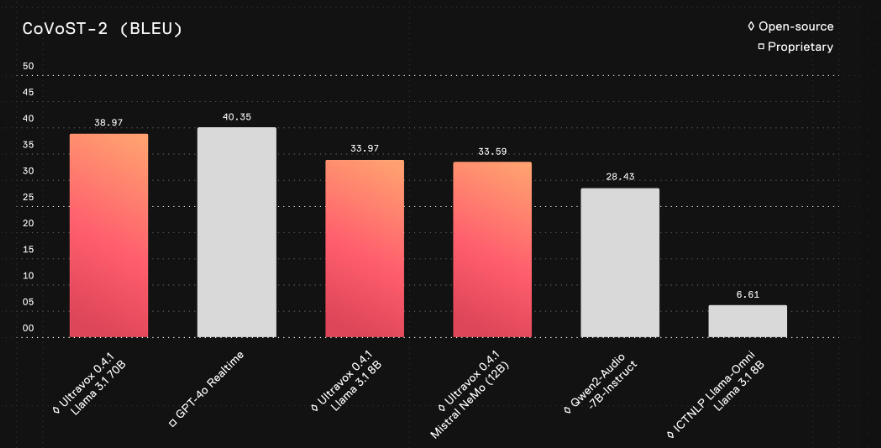
Technical features
Ultravox is able to process both text and speech input and convert the audio directly into the high-dimensional spatial data required by LLM without the need for an additional speech recognition (ASR) stage. This design makes the system more efficient in terms of response speed and resource consumption than traditional separate ASR and LLM systems.
2.Quick response:
When processing audio input, the current version of Ultravox 0.4 takes about 150 milliseconds to generate a token for the first time, and generates about 60 tokens per second, which has high real-time response capabilities. Although the performance is already high, the team believes that there is still room for further optimization.
3. Efficient model coupling:
Ultravox directly couples audio with the LLM model, avoiding the complex process of converting speech to text and then understanding it in traditional methods. This method significantly reduces processing latency and improves the model's ability to understand speech. In the future, it will also add the understanding of paralinguistic cues such as emotion and speech rhythm.
4. Flexible model training:
Ultravox supports users to conduct customized training based on different LLM (such as Llama 3, Mistral, Gemma, etc.) and audio encoders. Users can modify the configuration file, select different base models, and train adapters to improve performance in specific fields or languages.
5. Real-time inference with low resource requirements:
Ultravox's real-time inference is accessible via an API and supports input of audio content as WAV files. For application scenarios that require real-time speech understanding, Ultravox provides a flexible and efficient inference framework.
6. Support expansion and customization:
Ultravox allows users to train with their own audio data to add new language or domain knowledge. The training process supports large-scale parallel processing through platforms such as MosaicML, and can also be deployed in a local environment.
7. Future voice stream generation:
Ultravox currently supports converting speech to text, and will be expanded to generate speech streams (speech synthesis through vocoder) in the future. This means that Ultravox not only understands speech, but also responds in the form of natural speech.
8. Training and evaluation tools:
Ultravox provides a wealth of training and evaluation tools, allowing users to train their own models or conduct experimental evaluations. The model training process uses simple configuration files, supports multiple distributed training methods, such as DDP (distributed data parallel) training, and supports integration of tools such as WandB for experimental logging.
Project link